
 登錄
登錄
 注冊
注冊



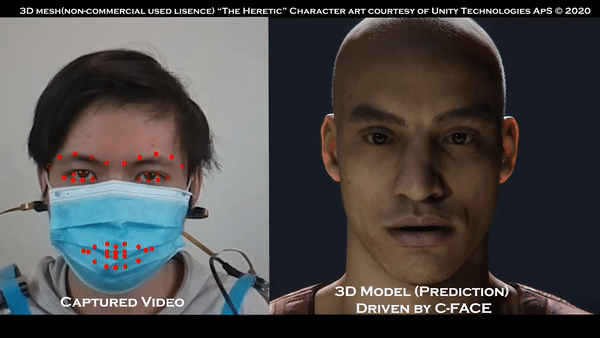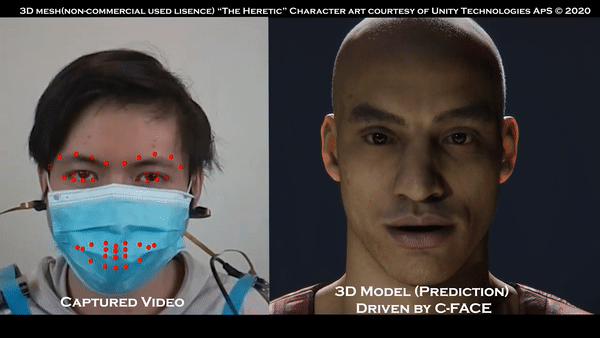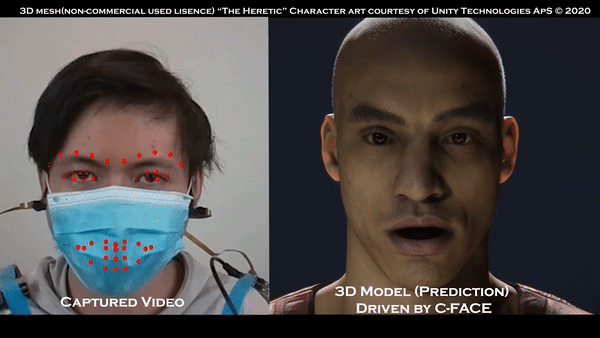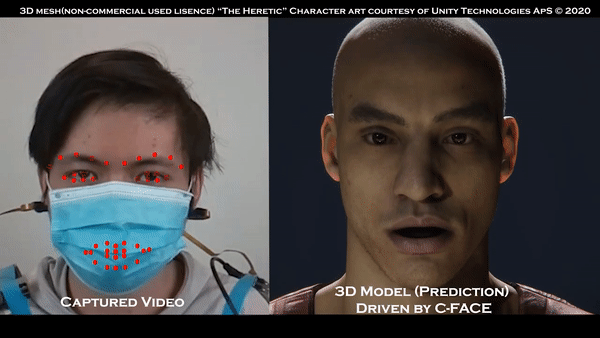

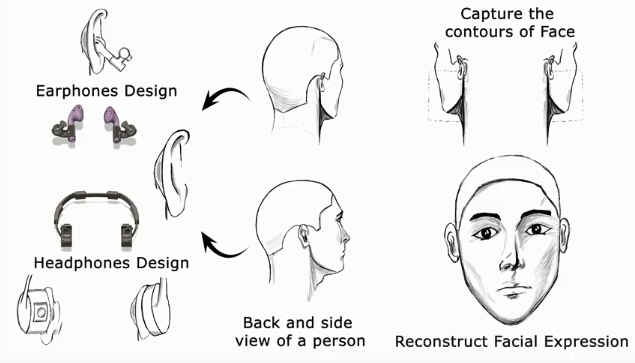








近期,在物聯(lián)網(wǎng)安全和隱私方面不僅在技術(shù)領(lǐng)域取得重要的成就,而且在世界范圍內(nèi)具有啟發(fā)性和方向性的研究逐漸呈現(xiàn)。

云里物里將以科技賦能,構(gòu)建物聯(lián)網(wǎng)運營新體系,致力于打造具有全球影響力的物聯(lián)網(wǎng)科技創(chuàng)新引領(lǐng)型企業(yè),帶領(lǐng)全國乃至全世界走進跨越設備、軟件和服務無縫鏈接的萬物互聯(lián)時代。

銓順宏長期以來堅持做“成功的”項目,這背后既離不開ThingMagic的技術(shù)優(yōu)勢,也離不開銓順宏豐富的項目實戰(zhàn)經(jīng)驗。







